Seed Sites & TrustRank – Quick Explainer
What are Seed Sites?
Seed Sites are a small, carefully selected set of high-trust, highly connected websites (e.g. major news media, government, universities) that a search engine uses as starting points for crawling and trust propagation. Because these domains sit at the centre of the web graph, their outbound links help search engines quickly discover and prioritise large parts of the web. Being closer to Seed Sites in the link graph usually means faster crawling, more reliable indexing and stronger perceived authority.
For a deeper SEO-focused discussion of Seed Sites and link value, see my IncRev SEO Research article
– “Best backlinks for SEO – how link value travels across the web and why some links matter more” on IncRev:
Best backlinks for SEO (IncRev SEO Research)
What is TrustRank?
TrustRank is a family of algorithms where search engines start from a manually curated list of trusted Seed Sites, then spread trust along outgoing links, with trust decaying as distance from the seeds increases. Pages near the seeds in the link graph gain more trust; pages far away or in “spammy” neighbourhoods gain little or none. This idea is closely related to Google’s distance-based ranking patents, where graph distance from trusted seeds is used as part of the ranking signal.
For a practitioner-friendly breakdown of how this works in modern SEO, see:
– IncRev Academy — Google TrustRank
And for the underlying distance-based ranking idea in the original patent literature, see:
– Google patent: “Producing a ranking for pages using distances in a web-link graph” (US9165040B1)
This post summarises my research paper:
Seed Sites for Crawling and Indexing UK Websites: A Mathematical Model of the .co.uk Web” – David Vesterlund, IncRev SEO Research (DOI: 10.5281/zenodo.17798620)
The full paper is available in the IncRev SEO Research community on Zenodo and on my Academia.edu page:
- Zenodo: https://zenodo.org/communities/increvseo
- Academia.edu: https://independent.academia.edu/DavidVesterlund
All simulation code, graphs and the Seed Site coverage tool are open source:
This blog version is intentionally shorter, practical and SEO-focused: no formulas, no derivations, no code – just what the results mean for crawling, indexing, SEO and Google-style ranking systems.
1. Why Seed Sites Matter for SEO
At web scale, a crawler can’t start from every site. Search engines rely on a relatively small set of Seed Sites – highly trusted, well-connected domains that act as starting points for crawling, indexing and indirectly for TrustRank-styletrust propagation.
If your site is:
- Close to Seed Sites in the link graph → you are likely crawled and re-crawled earlier (shorter TTFI – Time To First Index).
- Far away in the long tail → discovery is slower and more fragile, even if your content is good.
The paper asks a quantitative question for the co.uk web:
How many .co.uk Seed Sites does a search engine need to cover most active UK domains within 2–3 link hops?
…and then connects that to SEO, Google ranking and link building strategy.
2. Data & Model in One Paragraph
Very short version of the methodology:
- We model the .co.uk web as a domain-level link graph (PLD graph).
- We use:
- Nominet counts for total .co.uk domains (Sept 2025: ~8.4M).
- Common Crawl / Web Data Commons statistics to approximate how many other .co.uk domains each .co.uk domain tends to link to.
- We then simulate how far a crawl can reach in 2 hops and 3 hops:
- Hop 1: Seed Site → domains it links to
- Hop 2: those domains → other .co.uk domains
- Hop 3: and so on…
- We explicitly model:
- Intra-TLD homophily (how often .co.uk links to .co.uk)
- Deduplication (same domains seen multiple times)
- Overlap between neighbourhoods of different seeds.
The blog post skips the formulas and focuses on the outputs.
3. Two Hops: How Many Seeds for the UK Web?
We look at “active” .co.uk domains – sites with substantial content.
Two scenarios:
- 43% active (CENTR-based estimate)
- 50% active (sensitivity case)
Under the baseline link-graph assumptions, the model suggests:
- To reach 90% of active .co.uk sites within just 2 hops
- ~61,000 Seed Sites if 43% of .co.uk domains are active
- ~71,000 Seed Sites if 50% are active
To show the difference between 2-hop and 3-hop crawling, here is a compact summary.
Table 1 – Seeds needed for ~90% coverage of active .co.uk
| Model | Active share assumption | Approx. seeds for 90% coverage |
| 2 hops (baseline) | 43% active | ~61,000 |
| 2 hops (baseline) | 50% active | ~71,000 |
| 3 hops (baseline) | 43% active | ~8,000 |
(Exact table values in the paper; here we round to keep it readable.)
Key insight:
If a crawler insists on staying very shallow (2 hops only) and wants national-scale coverage, it may need tens of thousands of Seed Sites in the UK alone.
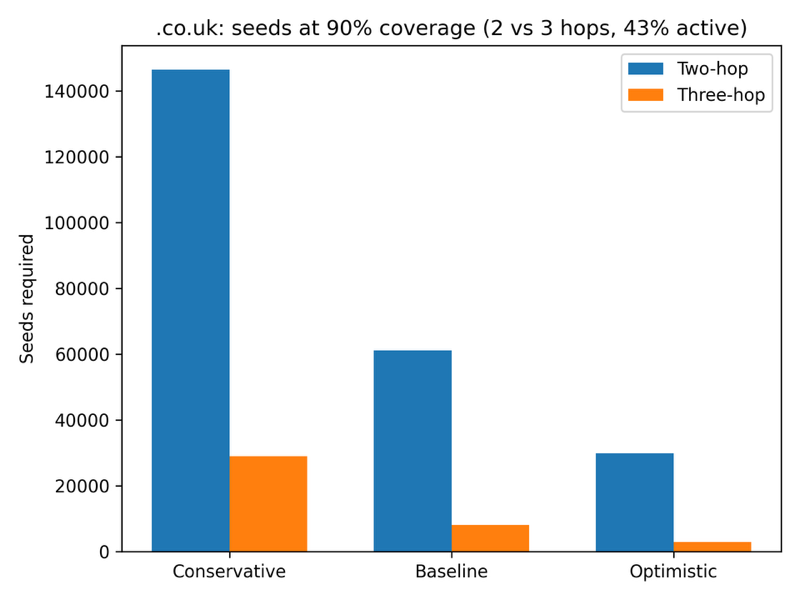
Figure 1 – Seeds required at 90 % coverage under the two‑hop model for UK
Seeds required at 90 % coverage under the two‑hop model, comparing 43 % and 50 % active‑share assumptions across conservative, baseline and optimistic scenarios.
4. Three Hops Change the Game
When we allow 3 hops instead of 2, coverage jumps dramatically:
- For the same baseline .co.uk model, a 3-hop crawl needs only about:
- 8,000 seeds to hit 90% coverage
- <9,000 seeds to hit 95% coverage
This highlights an important trade-off for search engines:
- Fewer seeds + more hops
→ smaller curated Seed set, more reliance on the broader web graph. - More seeds + fewer hops
→ more infrastructure and curation, but more controlled coverage and potentially faster TTFI.

Figure 2: Stylised TTFI vs number of seed sites for .co.uk
The Time to First Indexx goes down when the number of Seed Sites goes up.
Stylised TTFI vs number of seed sites for .co.uk under the baseline distance‑to‑seeds model, assuming fixed effective out‑degree and hop‑latency.
5. Toy Link Graph: What 5,000 Seeds Actually See
To make this more intuitive, the simulator also generates a toy web graph:
- ~100 domains as nodes
- Links between them based on a .co.uk-like structure
- A Seed set is placed on some nodes
- We colour nodes:
- Green = discovered within 2 hops
- Grey = still hidden even after 2 hops
In the full-scale .co.uk baseline simulation:
- With 5,000 Seed Sites and only 2 hops, the model finds about 64.5% of active .co.uk domains.
- In other words, roughly one-third of active UK sites are still “grey” – not reached by the 2-hop frontier.

- Figure 3 – Toy link graph with partial coverage
A small network diagram where green nodes cluster around Seed Sites and many grey nodes sit further out.
Caption: “Toy .co.uk link graph: with 5,000 Seed Sites and 2 hops, only about two-thirds of the web is covered.”
6. Sweden vs UK: Same Logic, Different Scale
To show how this model scales, we apply the same baseline structure to:
- UK (.co.uk) – ~8.4M domains
- Sweden (.se) – ~1.5M domains
Below is a simplified 2-hop baseline comparison from the paper (illustrative numbers):
Table 2 – 2-hop coverage and TTFI for UK vs Sweden (baseline scenario)
| Country | Seeds | Coverage (approx.) | Stylised TTFI (seconds)* |
| UK | 5,000 | 6.5% | 9.17 |
| 10,000 | 12.9% | 8.31 | |
| 20,000 | 25.8% | 7.46 | |
| 50,000 | 64.5% | 6.33 | |
| SE | 500 | 3.6% | 9.88 |
| 1,000 | 7.2% | 9.03 | |
| 2,000 | 14.5% | 8.17 | |
| 5,000 | 36.1% | 7.04 |
*TTFI values come from a simple distance-based model; they are relative, not log-based measurements.
Takeaways:
- A larger ccTLD (UK) needs many more Seed Sites to reach the same coverage percentage.
- Even with 5,000–10,000 seeds, a 2-hop crawl only reaches a modest slice of the active .co.uk graph.
- In a smaller ccTLD like .se, the same number of seeds buys you more relative coverage – but still not “everything”.
7. SEO Implications: Link Building, Google Ranking & Trust
So what does all of this mean in practical SEO terms?
7.1 Distance to Seed Sites matters
Even without modelling TrustRank directly in this paper, Seed Sites play two roles:
- Coverage anchors – deciding whether a domain gets discovered quickly at all.
- Trust anchors – as explored in my separate work on TrustRank and Seed Sites, where trust flows through the link graph and decays with distance.
For SEO and link building, this means:
- Links from sites that are closer to Seed clusters (major news, government, universities, large commerce sites, strong hubs) are doubly valuable:
- They make you easier to crawl and index.
- They likely carry more trust, because they sit closer to the trust “core” of the web graph.
7.2 Why SMEs and charities can get stuck in the long tail
If Seed sets and high-degree hubs are dominated by:
- National media
- Large brands
- Central institutions
…then local trades, regional news, charities, niche B2B players tend to sit further away in the link graph.
That shows up as:
- Longer TTFI
- More fragile indexing
- Lower probability of being present in the index at any given moment, even before we talk about content quality or on-page SEO.
This is a structural bias baked into the link graph. The paper argues that Seed selection strategies could:
- Either maximise pure coverage (centrality-first)
- Or deliberately diversify coverage (fairness-aware seeding) by including more SMEs, regions and sectors.
7.3 Practical takeaways for SEOs
For practitioners and SEO teams, this research suggests:
- Think in terms of distance to Seed Sites, not just “get links from authority domains”.
- Aim for:
- Links from national or sector hubs (news, associations, large marketplaces).
- Links that bridge you closer to the Seed core (universities, government, big brands in your vertical).
- Expect that:
- A site with strong links from central hubs will typically have shorter TTFI and more stable presence.
- A site that only has “sideways” links within the long tail risks being structurally under-crawled.
8. Explore the Tools, Data & Full Paper
If you want to dig deeper, reproduce the tables or generate your own coverage graphs and toy link graphs:
- Full paper & related preprints
- Zenodo community: https://zenodo.org/communities/increvseo
- Academia.edu: https://independent.academia.edu/DavidVesterlund
- Code, simulator & plotting scripts
- GitHub repository: https://github.com/VesterlundCoder/SEO-SeedSites
The repository includes:
- A Python simulation tool for Seed coverage and TTFI.
- Scripts to generate:
- Coverage vs seeds curves
- TTFI vs seeds curves
- Toy link graph visualisations showing covered vs uncovered nodes.