Som SEO har du säkert hört ord som embeddings, vektorer och cosine similarity dyka upp allt oftare. Men vad betyder det egentligen – och varför ska du bry dig om vinklar i ett matematiskt rum när du bara vill få mer organisk trafik?
I den här artikeln förklarar jag cosine similarity på ett sätt som går att använda i verkliga SEO-beslut: vilka sidor som matchar en sökfråga, vilka stycken som bör skrivas om, och vilka länkar som är relevanta på riktigt.
Snabba fakta: Detta är Cosine Similarity (TL;DR)
- Vad är det? Ett matematiskt mått på hur lika två texter är rent innehållsmässigt.
- Hur mäts det? På en skala från ungefär 0 (helt olika) till 1 (identisk betydelse).
- Varför bry sig? Det är grunden i hur moderna sökmotorer – och verktyg som ChatGPT – förstår relevans. Det ersätter gamla mått som ren keyword density.
- Viktigast för SEO: Används för att matcha sökintention, hitta duplicerat eller svagt innehåll och värdera hur relevant en länk faktiskt är.
1. Från nyckelord till semantisk SEO
För tio–femton år sedan handlade SEO om att matcha bokstäver. Om användaren sökte på ”billiga hotell” ville Google se frasen ”billiga hotell” så många gånger som möjligt på din sida. Ofta räckte det med att trycka in exakt samma fras i rubrik, brödtext och alt-taggar.
Idag handlar SEO om betydelse – semantik. Google vill förstå att:
• ”billigt boende”
• ”prisvärda övernattningar”
• ”budgethotell”
kan betyda samma sak för användaren, även om orden ser olika ut.
För att göra det måste datorn sluta se ord som bara textsträngar och börja se dem som koncept. Och för att kunna räkna på koncept behöver vi en matematisk representation: vi måste förvandla text till siffror. Det är där vektorer och cosine similarity kommer in.
Vill du se hur vi använder det här för att mäta topical authority och innehållsgap? Läs mer om vårt QueryMatch-verktyg för topical authority.
2. Vad är en vektor – för en SEO?
Tänk dig att vi har ett gigantiskt, osynligt rum. I det rummet svävar alla ord i språket som små punkter.
• Ord som hör ihop – till exempel ”SEO-konsult”, ”sökmotoroptimering”, ”digital marknadsföring” – ligger nära varandra.
• Ord som ”barista”, ”kaffebönor” och ”espressomaskin” bildar ett annat kluster.
• Ord som ”bilmekaniker” och ”vinterdäck” hamnar på ett tredje ställe.
Moderna språkmodeller – som BERT, LaBSE och olika Sentence-BERT-varianter – har tränats på miljarder meningar för att lista ut var i rummet varje text ska hamna.
Är du intresserad av exakt hur vi hämtar dessa vektorer med Python? Missa inte vår guide: ”Semantic SEO & Vectorization: From Theory to Python”
För den matematiska grunden, se vår researchrapport ”Mathematical Foundations of Text Vectorization and Sentence-BERT”.
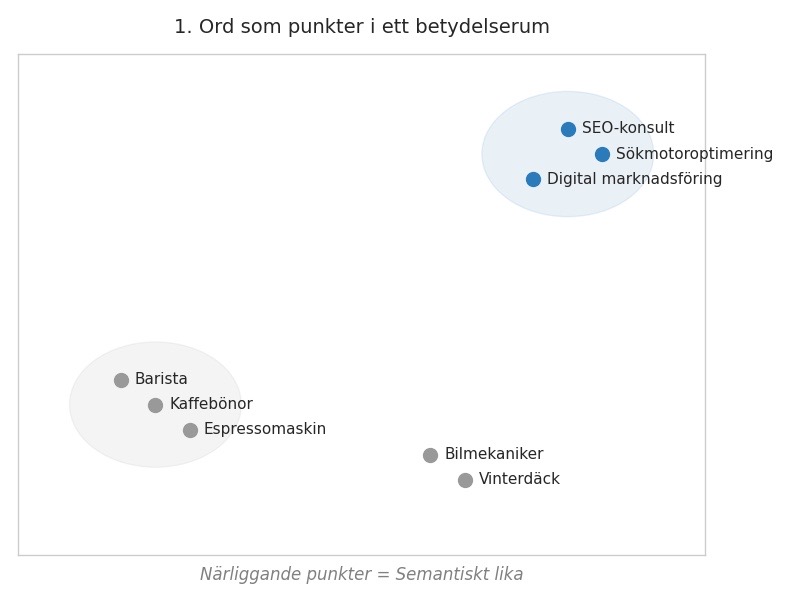
Figur 1. Ord som punkter i ett betydelserum. Närliggande punkter = semantiskt lika.
3. Vad är cosine similarity – med SEO-glasögon?
När vi väl har två vektorer, till exempel en vektor för sökfrågan ”SEO tips” och en vektor för din artikel ”Guide till SEO”, vill vi veta: pratar de om samma sak?
Det naiva sättet vore att mäta avståndet mellan dem. Men det finns ett problem: en kort sökfråga och en lång artikel får olika ”längd” på sin pil, även om de handlar om exakt samma ämne.
Därför tittar vi istället på vinkeln mellan vektorerna. Det är det som är cosine similarity:
• Liten vinkel = pilarna pekar åt samma håll → hög likhet.
• Stor vinkel = pilarna pekar åt olika håll → låg likhet.
Matematiken bakom ger oss i praktiken ett tal mellan 0 och 1 för textlikhet:
• 1.0 ≈ exakt samma betydelse eller extremt lika texter.
• 0.0 ≈ ingen semantisk likhet alls.
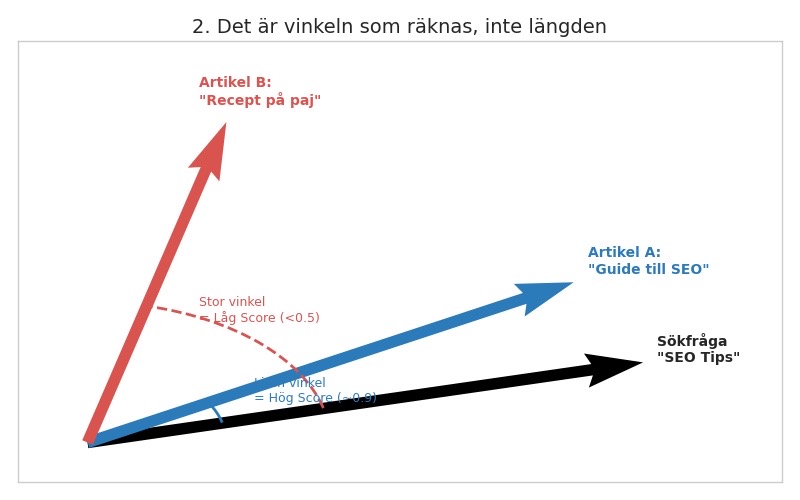
Figur 2. Det är vinkeln som räknas, inte längden.
4. Hur du tolkar siffrorna i praktiken (Score Guide)
När du börjar använda verktyg eller Python-script för att analysera din sajt kommer du få ut en massa decimaltal som 0.93, 0.78, 0.61 och 0.42. För att göra det användbart behöver du en lathund. Nedan ser du en visuell skala och en tabell som du kan använda i ditt dagliga SEO-arbete.
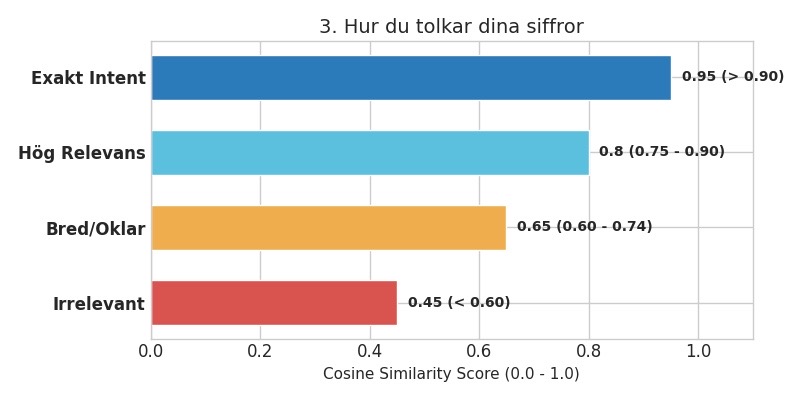
Figur 3. Hur du tolkar cosine similarity-siffror för SEO.
| Score (likhet) | Betydelse för SEO | Rekommenderad åtgärd |
| 0.90 – 1.00 | Extremt hög relevans. Texten svarar nästan exakt på frågan. | Perfekt. Rör så lite som möjligt – denna sida/sektion är ”on point”. |
| 0.75 – 0.89 | Hög relevans. Bra matchning mot sökintentionen. | Detta är din ”money zone”. Prioritera att stärka dessa sidor med internlänkar och E-E-A-T. |
| 0.60 – 0.74 | Bred/oklar matchning. Berör ämnet men kanske inte kärnan. | Granska innehållet. Behöver sidorna skrivas om eller spetsas mot en tydligare intent? |
| < 0.60 | Låg relevans. Troligen off-topic eller brus. | Om detta är din landningssida för ett viktigt sökord har du problem – byt sida eller skriv nytt. |
5. Tre sätt att använda cosine similarity för att ranka bättre
5.1 Hitta content decay och irrelevanta stycken
Istället för att bara titta på hela sidan kan du bryta ner en text i stycken eller sektioner.
1. Embedda varje stycke (gör dem till vektorer).
2. Jämför varje stycke mot huvud-sökfrågan eller det topic-kluster sidan är tänkt att tillhöra.
3. Beräkna cosine similarity för varje stycke.
Stycken med hög score (≥ 0.75) bär sidan. Stycken med låg score (< 0.6) spårar ur, babblar eller byter ämne. Det här ger dig en exakt lista över vilka stycken som ska skrivas om först, istället för att gissa vad som är svagt.
5.2 Semantisk internlänkning
De flesta internlänkar sätts på magkänsla: ”Det här känns relaterat – vi länkar hit.” Med cosine similarity kan du göra det datadrivet.
1. Skapa vektorer för båda sidorna du tänker länka mellan.
2. Räkna cosine similarity.
• Är värdet > 0.8? Länken är semantiskt superrelevant – bra för både användare och sökmotor.
• Är värdet < 0.5? Länken är troligen brus och späder ut din topical authority.
På så sätt kan du bygga internlänkar som faktiskt förstärker dina tematiska kluster. Det är precis så vi tänker i vårt QueryMatch-verktyg.
5.3 Värdera backlinks: trust och relevans
Alla länkar är inte lika mycket värda. En länk från en domän med hög DR/UR kan vara nästan värdelös om den inte är tematiskt relevant.
Cosine similarity låter dig kombinera graf-baserad trust (länknätet, TrustRank) med semantisk relevans.
• Ta texten runt länken (anchor + närmaste meningar).
• Embedda den och landningssidan.
• Räkna cosine similarity.
Det här bygger vidare på vårt arbete med TrustRank, seed sites och länkvärde i Google-liknande system.
6. Vanliga missförstånd om cosine similarity i SEO
“Det här är bara en lite smartare keyword density”
Nej. Keyword density tittar bara på hur ofta ett ord förekommer. Cosine similarity tittar på hela betydelsen av texten – även synonymer, omformuleringar och kontext. En text kan ha låg keyword density men hög cosine similarity om den besvarar frågan på ett naturligt sätt.
“Hög cosine betyder att sidan är perfekt”
Inte nödvändigtvis. En sida kan vara semantiskt träffsäker men ändå vara för tunn, sakna E-E-A-T eller ha tekniska problem. Cosine similarity är ett relevansmått, inte ett komplett kvalitetsmått.
“En embedding-modell kan ersätta all SEO-analys”
Embeddings och cosine similarity är ett kraftfullt lager i analysen, men de ersätter inte teknisk SEO, länkanalys, användarbeteende eller konkurrenssituationen i SERP:en. Tänk på det som ett sätt att sluta gissa om relevans – inte som en magisk ranking-knapp.
7. Hur cosine similarity knyter ihop din SEO-stack
Cosine similarity är inte ett isolerat trick – det är en byggsten i flera av våra forskningsspår:
• QueryMatch & topical authority – vi använder cosine similarity för att se hur väl hela ditt innehållskluster matchar en grupp sökfrågor.
• LaBSE-proxies & embeddingsval – genom att jämföra cosine-siffror mellan olika modeller och Googles LaBSE kan vi hitta billiga embeddings som beter sig likt LaBSE.
• SeedTrust & länkbaserad trust – när vi modellerar trust-grafer för den svenska webben kan cosine similarity väga in hur tematiskt relevant en länk är, inte bara hur nära en seed-nod den ligger.
8. Nästa steg – från förståelse till praktik
Nu vet du vad cosine similarity är, hur du tolkar siffrorna och tre konkreta sätt att använda det i innehåll, internlänkning och länkbygge.
Vill du gå vidare och göra detta i skarp drift?
• För matematiken bakom: läs vår researchrapport ”Mathematical Foundations of Text Vectorization and Sentence-BERT”.
• För praktisk implementation i Python: vår guide ”Semantic SEO & Vectorization: From Theory to Python”.
• För verktygsnivå: se hur vi bygger topical authority-analys i QueryMatch.