How to audit content relevance and link quality using Sentence-Transformers
1. Introduction – Semantic SEO You Can Actually Compute
“Semantic SEO” is no longer a buzzword. It’s a computable metric.
You don’t have to guess whether Google (or any modern search engine) thinks your page is relevant to a query. With today’s embedding models you can measure relevance using the same type of math search engines rely on internally: text vectorization + cosine similarity.
In this article we’ll take that idea and turn it into working Python code you can run on your own site. We’ll:
– map keywords to the best landing page,
– find paragraphs that dilute your topical authority,
– and score backlinks using a two-factor model: organic traffic health + semantic relevance.
For a non-technical, Swedish introduction to vectors, angles and cosine similarity, see: “Why Every SEO Must Understand Cosine Similarity (Without Being a Mathematician)” – the intuition behind the math.
2. TL;DR – What You’ll Build Today
By the end of this guide, you’ll have Python code to:
1. Map Queries to Pages (Intent Audit): Automatically find which page is the best semantic match for a keyword using cosine similarity.
2. Audit Content Drift (Paragraph Audit): Split a long article into paragraphs and find which sections pull you off-topic and weaken your topical authority.
3. Score Backlinks with a Two-Factor Model (Link Audit): Combine Organic Traffic Health and Semantic Relevance to classify links as gold, niche gems, authority padding, or waste.
We’ll use the sentence-transformers library, a few standard SEO-friendly models, and minimal boilerplate so you can plug this into your own workflow.
For more information on this, read more about the INCREV QueryMatch Tool, an AI-Powered Content Analysis Tool That Measures Relevance Like LLM and AI Search.
3. Setup: The “Standard SEO Environment”
To keep this practical, we’ll use what I call the Standard Increv Stack for Semantic SEO:
pip install sentence-transformers pandas numpy scikit-learn
That’s all you need for this article.
3.1 Recommended Models for SEO
Different embedding models trade off speed, accuracy and language coverage. Here’s a simple comparison to help you choose:
| Model Name | Language | Size (MB) | Best For |
| all-MiniLM-L6-v2 | English | ~80 MB | Speed. Great for quick audits of 1,000+ pages. |
| paraphrase-multilingual-MiniLM-L12-v2 | 50+ languages | ~420 MB | International SEO. Good balance of quality & speed. |
| sentence-transformers/LaBSE | 109 languages | ~1,800 MB | Accuracy. Best proxy for Google-like understanding. |
For experiments and demos, all-MiniLM-L6-v2 is usually enough. For serious multilingual analysis or high-stakes decisions, you’ll want a LaBSE-like model.
For a research-grade benchmark of which models best approximate Google’s LaBSE behaviour, see my paper “High-Fidelity Proxies for Google LaBSE”.
4. Use Case 1: Matching Queries to Pages (The Intent Audit)
Classic SEO question:
“I have 200 blog posts and 300 product pages – which page should be the canonical landing page for this keyword?”
Historically, you answered that with a mix of gut feeling, on-page keyword checks, and maybe some TF-IDF scores.
With embeddings, you can let the model decide which page is semantically closest to the query.
4.2 The Code
Below is a minimal working example. It takes one query and three candidate pages and ranks them by cosine similarity:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer(“all-MiniLM-L6-v2”)
query = “best technical seo tools”
pages = [
“Top 10 Marketing Software for 2024”,
“Ultimate Guide to Technical SEO Audits”,
“How to bake pancakes”
]
query_emb = model.encode(query, convert_to_tensor=True)
page_embs = model.encode(pages, convert_to_tensor=True)
scores = util.cos_sim(query_emb, page_embs)[0]
for score, page in sorted(zip(scores, pages), reverse=True, key=lambda x: x[0]):
print(f”Score: {score:.4f} | Page: {page}”)
Extend this by loading hundreds of URLs with their content from a CSV and ranking them in one go.
4.3 Visual Output – Query → Page Ranking
Imagine we run a similar script for the query “Best software for SEO” and evaluate several pages. A visual bar chart might look like this:
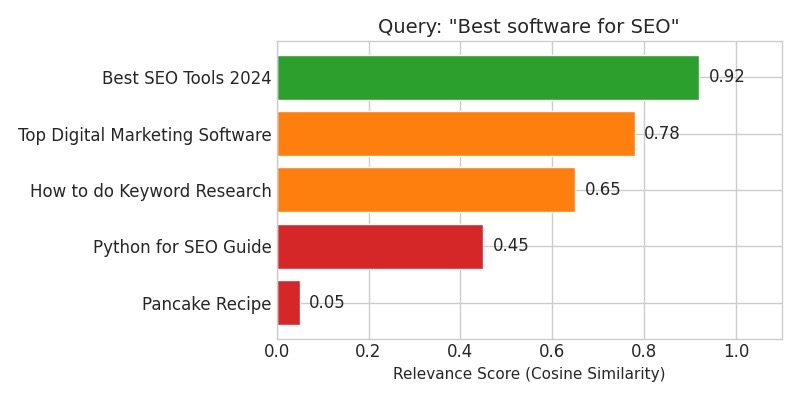
Figure 1 – Query: “Best software for SEO”. The model ranks pages by cosine similarity (semantic relevance).
4.4 How to Interpret the Scores
As a practical rule of thumb:
• Score > 0.75 → This page is a strong candidate for the target keyword.
• Score 0.60 – 0.75 → Related, but not perfect; better suited to long-tail or supporting topics.
• Score < 0.50 → Essentially off-topic; if this is your current landing page, you likely have a mapping problem.
For a detailed “score-to-action” guide, see the cosine similarity article where I map ranges like 0.6, 0.8, 0.9 to concrete SEO decisions.
5. Use Case 2: Finding Content Drift (Paragraph-Level Audit)
Long-form content is powerful for building topical authority – but only if you stay on topic.
In reality, many articles drift: the intro is great, the first sections are solid, then somewhere in the middle the writer starts telling a personal story or goes off on a tangent.
From a semantic point of view, those paragraphs lower the average relevance of the page and send mixed signals to both users and search engines.
5.2 The Code Concept
We can detect this automatically:
1. Take the page’s main topic (e.g. the H1 or target query).
2. Split the content into paragraphs.
3. Compute cosine similarity between the topic embedding and each paragraph embedding.
4. Flag paragraphs with low scores.
Pseudo-code:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer(“all-MiniLM-L6-v2”)
page_topic = “technical seo audit”
paragraphs = […] # list of paragraph texts
topic_emb = model.encode(page_topic, convert_to_tensor=True)
para_embs = model.encode(paragraphs, convert_to_tensor=True)
scores = util.cos_sim(topic_emb, para_embs)[0].cpu().tolist()
5.3 Example Input Table
| Paragraph ID | Text Snippet | Score vs “Technical SEO” | Action |
| P1 | Technical SEO is about crawling and indexing… | 0.92 | Keep |
| P2 | First, check your robots.txt file… | 0.88 | Keep |
| P3 | My grandmother loved baking cookies… | 0.15 | DELETE |
5.4 Visual Output – Paragraph Heatmap
To make this audit easy to digest, plot paragraph scores as a simple heat strip:
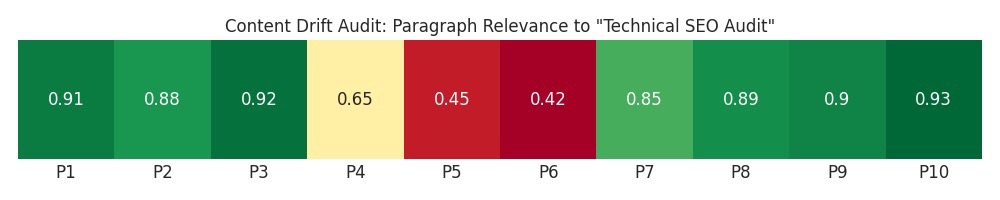
Figure 2 – Content drift audit: paragraph relevance to “Technical SEO Audit”. Green = on-topic, red = off-topic.
6. Use Case 3: The Two-Factor Link Relevance Score
Most link metrics answer “How strong is this domain?” (DR/DA/UR). At IncRev we treat that as only half the picture.
A high-DR domain with weak or declining organic traffic is often a sign of decay or penalisation, or poor content clusters without the topical structure that Google rewards today.
For us, a website’s Organic Traffic Volume and Trend is a hard gatekeeper. It’s a proxy that the site publishes good content, has reasonably clear topical clusters, is technically healthy, and is currently appreciated by Google.
6.1 IncRev Traffic Thresholds (The Gatekeeper)
| Monthly Organic Traffic | IncRev Traffic Flag | Interpretation |
| < 1,000 | Red Flag | Immediate disqualification (risky / unproven / penalised). |
| 5,000 – 10,000 | Yellow Flag | Good for niche/B2B. Requires manual trend verification. |
| > 10,000 | Green Zone | Qualified. Proceed to semantic relevance scoring. |
| > 50,000 | Dream Scenario | Consistently winning high-competition keywords. |
The Trend Rule: Traffic must be flat or growing over the last 6, 12 and 24 months. A plummeting trend – regardless of current volume – is an immediate Red Flag.
Only when a site passes this “Traffic Health” gate do we apply the semantic layer.
6.2 The Two-Factor Link Audit
Once a domain passes the traffic test, we apply the Semantic Relevance layer:
Semantic Relevance = cosine(anchor_context, target_page_content)
This gives us a two-step decision:
1. Traffic Check: Is this domain getting enough healthy organic traffic to be considered “trusted by Google”?
2. Semantic Check: Is this particular link context actually about the same thing as the target page?
Example logic in Python:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer(“all-MiniLM-L6-v2”)
link_data = {
“traffic”: 15000,
“traffic_trend”: “growing”,
“anchor_context”: “This new study on vectorization proves that traditional keyword-only SEO is no longer enough.”,
“target_content”: “Our ultimate guide to semantic SEO, vector embeddings and cosine similarity for technical SEOs.”
}
def qualify_link(data):
if data[“traffic”] < 1000 or data[“traffic_trend”] == “declining”:
return “Red Flag / Disqualify”
ctx_emb = model.encode(data[“anchor_context”], convert_to_tensor=True)
tgt_emb = model.encode(data[“target_content”], convert_to_tensor=True)
score = util.cos_sim(ctx_emb, tgt_emb).item()
if score >= 0.85 and data[“traffic”] >= 10000:
return f”GOLD MINE ({score:.2f})”
elif score >= 0.70 and data[“traffic”] < 10000:
return f”NICHE GEM (Traffic Yellow Flag) ({score:.2f})”
else:
return f”AUTHORITY PADDING ({score:.2f})”
6.3 Visual Output – The IncRev Link Qualification Matrix
The real power appears when you visualise these two factors together: Monthly Organic Traffic (x-axis, log scale) and Semantic Relevance (y-axis, cosine score).
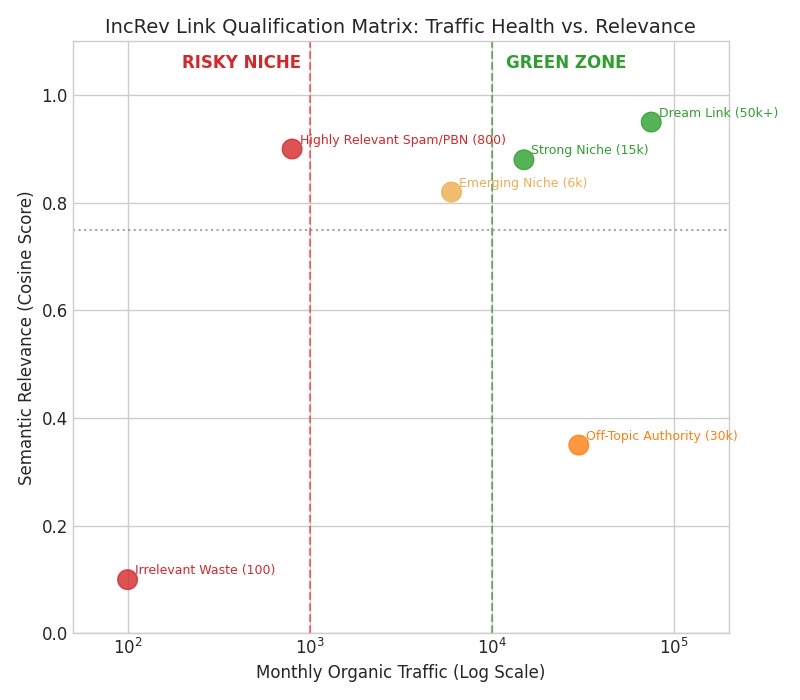
Figure 3 – IncRev Link Qualification Matrix: Traffic Health vs. Semantic Relevance.
6.4 Quadrants & Actions
| Quadrant (Traffic × Relevance) | Classification | Action |
| High Traffic, High Relevance | GOLD MINE / Dream Link | Highest priority. Build and maintain the relationship. |
| High Traffic, Low Relevance | Authority Padding | Good for brand & PR; weak for topical authority. |
| Low Traffic, High Relevance | Risky Niche Gem | Only accept if traffic trend is clearly growing. High risk, high reward. |
| Low Traffic, Low Relevance | Waste / Toxic | Do not spend time securing or keeping these links. Consider disavow. |
Instead of chasing DR/DA scores in isolation, you now use:
1. Traffic Health as a proxy for whether Google actually likes the site today.
2. Semantic Relevance to confirm the link strengthens your topical graph, not just your raw link count.
This builds directly on the trust-based modeling work in my paper “TrustRank and Seed Sites – Modeling Backlink Value for Web Trust Propagation in a Google-Like Ranking System.”
7. Conclusion & Next Steps
What we did in this article is essentially build a mini semantic SEO lab:
1. Embed your content – use Sentence-Transformers to convert queries, paragraphs and link contexts into vectors.
2. Measure relevance – use cosine similarity to quantify query→page, paragraph→topic and link-context→target fits.
3. Add traffic health & act on the numbers – only trust links from domains with healthy, stable or growing organic traffic; use semantic scores to prioritise Gold Mine links and identify Risky Niche Gems; rewrite or remove paragraphs that drag your relevance down; and map keywords to the pages that actually match searcher intent.